인프런 - AI 시대에도 살아남는 엔지니어의 조건, 미국 빅테크 시스템 디자인, 알고리즘 사고, 오픈소스 실무 완성
+ 요즘 개발자를 위한 시스템 설계 수업 (길벗)
서비스 규모가 확장되고 애플리케이션은 복잡해지고
사용자 수가 늘어나면서 기존 데이터 검색 및 저장 방식을 저해하는 병목 현상이 발생할 수 있습니다.
이러한 성능 문제를 해결하기 위한 효과적인 방법중 하나가 바로 캐싱입니다.
캐싱은 애플리케이션이나 사용자와 가까운 위치에 데이터를 임시로 저장하여 보다 빠르게 접근할 수 있도록 하는 기법입니다.
주로 저장소 계층(캐시)에 저장하며, 메모리, 디스크, 네트워크 등 다양한 위치에 있습니다.
애플리케이션이 커지고 여러 서버나 데이터 센터에 분산되면 단일 캐시만으로는 충분하지 않을 수 있습니다.
이때, 분산 캐싱이 등장합니다.
각 캐시노드는 자신만의 자료를 가지고, 네트워크로 연결되어 사용자가 원하는 데이터를 빠르게 찾도록 돕습니다.
캐싱이란
캐싱 주요 개념
캐시
자주 접근하는 데이터나 리소스의 복사본을 임시로 저장하는 공간
하드웨어 캐시(CPU 캐시), 소프트웨어 기반 캐시(인 메모리 캐시) 형태가 있습니다.
캐싱된 데이터
캐시에 저장된 데이터의 복사본
캐시 히트
요청한 데이터가 캐시에 있을 때를 의미합니다.
캐시 미스
요청한 데이터가 캐시에 없을 때를 의미합니다.
이 경우 시스템은 원본 데이터 소스에서 데이터를 가져오고, 이후에 빠르게 조회하기 위해 해당 데이터를 캐시에 저장합니다.
캐시 제거
저장소 캐시관리를 위해 시스템은 빈도가 적거나 최근에 사용하지 않은 데이터를 삭제하여 공간을 확보합니다.
캐싱 전략
Write-Through Caching
데이터베이스와 캐시 동시에 업데이트하는 방식으로 데이터의 일관성을 보장합니다.
항상 캐시는 최신데이터를 가집니다.
장점 : 데이터 유실 위험이 적습니다.
단점 : 쓰기 작업 시 데이터베이스에 매번 접근하므로 지연시간이 발생합니다.
적합한 경우 : 데이터 일관성이 매우 중요한 경우(ex. 사용자프로필 정보, 결제 데이터)
Write-Behind Caching
캐시에 먼저 쓰고 비동기(Batch)로 데이터베이스에 나중에 쓰는 방식입니다.
고성능이 필요한 전략입니다.
장점 : 쓰기 작업의 응답속도가 매우 빠릅니다.
단점 : 캐시 장애 시 데이터 유실 위험이 있습니다.
적합한 경우 : 쓰기 작업이 빈번하고 고성능이 필요한 경우 (ex. 실시간 로그수집, 게임 점수 갱신, 소셜 좋아요 기능)
Cache-Aside Strategy (Lazy Loading)

애플리케이션이 먼저 캐시 확인 후 없으면 원본 데이터베이스에서 가져옵니다.
이후 캐시에 없는 데이터를 저장해서 업데이트합니다.
가장 일반적인 캐싱전략입니다.
장점 : 필요한 데이터만 캐시로 저장하므로 효율적이고 장애시에도 DB가 살아있으면 서비스가 가능합니다.
단점 : 최초 조회시 캐시 미스가 발생하면 DB 조회 시간이 늘어납니다.
적합한 경우 : 읽기 작업이 많은 일반적인 서비스 (ex. 게시판 조회, 상품정보)
Refresh-Ahead Strategy
캐시 만료 전 미리 데이터를 갱신합니다.
캐시에 미리 올려두는 전략으로 일정한 패턴으로 데이터를 읽을때 유리합니다.
장점: 읽기 지연(Latency)을 거의 제로에 가깝게 유지할 수 있습니다.
단점: 데이터 사용 패턴이 불규칙하면 불필요한 DB 자원 낭비가 발생합니다.
적합한 경우: 데이터 접근 패턴이 매우 규칙적이고 예측 가능한 경우 (예: 매시간 업데이트되는 환율, 날씨 정보)
분산캐싱
분산 캐싱(distributed caching)은
데이터에 더 빠르게 접근할 수 있도록 여러 서버나 노드에 자주 사용하는 정보를 메모리에 분산 저장하는 기술입니다.
분산 캐싱의 핵심 목표는 디스크 기반 저장 시스템에서 데이터를 읽는 데 걸리는 속도문제를 해결하는 것에 있습니다.
디스크 기반이 아닌 여러 노드의 메인 메모리에 캐시를 저장해두면 디스크 입출력(I/O)으로 지연없이 자주 사용하는 데이터를 가져올 수 있습니다.
대표적인 분산 캐시 솔루션들을 보면서 좀더 확인해보겠습니다.
Memcached
memcached - a distributed memory object caching system
What is Memcached? Free & open source, high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load. Memcached is an in-memory key-value store for s
memcached.org
분산 메모리 캐싱 시스템으로, 데이터베이스 부하를 줄이고 빠른 응답을 제공합니다.
고성능 분산 메모리 객체 캐싱 시스템의 시초라고 볼 수 있습니다.
특징
멀티쓰레드 아키텍처 : 여러 CPU 코어를 효율적으로 활용합니다
데이터 비영구성 (메모리 기반으로 재시작시 데이터 손실)
LRU(Least Recently Used) 정책 : 메모리 용량이 가득차면, 가장 오랫동안 사용되지않는 데이터를 삭제하고 새 데이터를 저장
단순성 : 복잡한 기능 대신 Key-Value 로 집중하여, 오버헤드를 줄였습니다.
분산 아키텍처 : 여러 서버에서 실행될 수 있으며, 캐시를 서버 전체에 분산시켜 부하를 균형있게 다룹니다.
아키텍처
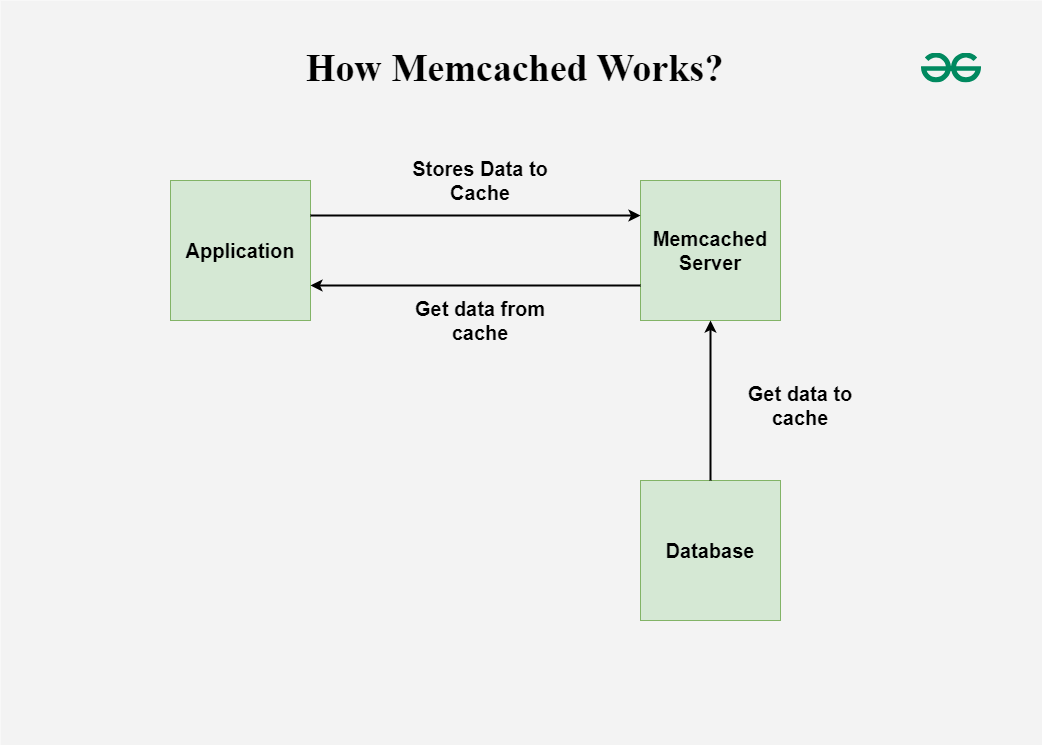
클라이언트-서버 아키텍처
클라이언트는 Memcached 서버와 통신하여 데이터를 저장하고 검색합니다.
이러한 분리 구조를 통해 여러 클라이언트가 동시에 캐시에 접근하고 서버 간 부하를 분산시킵니다.
해싱
일관된 해싱 알고리즘(Consistent Hashing)을 사용하여 키를 특정 서버에 매핑합니다.
이를 통해 각 키가 동일한 서버에 매핑되어 서버 간 데이터가 예측 가능하고 균형있게 분산됩니다.
동작방식
- Client Library: 애플리케이션 측 라이브러리가 Consistent Hashing 알고리즘을 사용해 데이터를 저장할 캐시 서버(노드)를 결정합니다. 즉, 모든 결정권은 클라이언트에 있습니다.
- Cache Node (Memcached Server): 중앙 집중식 관리자가 있는 것이 아니라, 클라이언트가 데이터를 분산해서 저장하는 구조입니다 (Shared-nothing).
- 메모리 할당: Slab Allocator 방식을 통해 메모리 단편화를 방지하고 고정된 크기의 슬랩에 데이터를 저장하여 빠른 접근을 보장합니다.
미리 할당 (Pre-allocation): Memcached는 시작할 때 큰 메모리 블록을 미리 확보하고, 이를 Slab이라는 단위로 나눕니다.
Slab과 Chunk: 각 Slab은 다시 정해진 크기의 Chunk들로 쪼개집니다.
100바이트 데이터가 들어오면 100바이트 Chunk들이 모인 Slab에 저장합니다.
이렇게 하면 데이터 크기가 제각각이어도 빈 공간을 찾는 데 시간이 걸리지 않고, 할당/해제 속도가 매우 빠릅니다.
단편화 제거: 메모리 관리를 직접 하기 때문에 운영체제(OS) 수준의 복잡한 메모리 할당 루틴을 거치지 않아 응답 시간이 일정하게 유지됩니다.
흐름도
| 단계 | 동작 | 설명 |
| Step 1 | 요청 | 클라이언트가 Key를 해싱하여 특정 서버 노드 결정 |
| Step 2 | 캐시 확인 | 해당 노드 메모리 내 Chunk 조회 |
| Step 3-A | Cache Hit | 캐시 데이터 즉시 반환 |
| Step 3-B | Cache Miss | DB에서 데이터 조회 후 캐시 저장(Set) 및 반환 |
분산방식
Memcached는 서버끼리 서로 통신하지 않습니다.
Redis와 달리, Memcached 서버 노드들은 서로 데이터를 복제하거나 클러스터 상태를 공유하지 않습니다.
데이터 분산 책임은 전적으로 클라이언트(애플리케이션)에게 있습니다.
그래서 서버를 추가하거나 뺄 때 데이터가 흩어질 위험이 있어, Consistent Hashing 기술이 필수적으로 동반됩니다.
Memcached는 스마트 클라이언트 구조를 채택하여, 클라이언트가 데이터를 분산(Sharding)하여 저장하므로 서버는 오직 메모리 작업에만 집중할 수 있습니다
Redis
Redis - Real-time data for agents & apps
Developers love Redis. Unlock the full potential of the Redis database with Redis Enterprise and start building blazing fast apps.
redis.io
Redis는 고성능 메모리 기반 데이터 구조 스토어(In-Memory Data Structure Store)입니다.
단순히 데이터를 메모리에 임시로 캐싱하는 용도를 넘어서,
다양한 형태의 데이터 구조와 데이터 영구 저장 기능까지 제공하는 강력한 도구입니다.
Redis의 핵심 특징
- 다양한 데이터 구조 지원: 단순한 Key-Value 형태의 문자열(String)뿐만 아니라, 리스트(List), 해시(Hash), 셋(Set) 등 복잡한 데이터 구조를 기본적으로 지원하여 개발의 편의성을 높입니다.
- 데이터 영구 저장 옵션 (Persistence): 인메모리 스토어의 한계를 극복하기 위해 AOF (Append Only File) 또는 RDB (Redis Database) 방식으로 데이터를 디스크에 영구 저장할 수 있습니다.
- Pub/Sub 기능: 발행/구독(Publish/Subscribe) 모델을 지원하여, 비동기 작업이나 마이크로서비스 간의 강력한 메시지 브로커(Message Broker)로 활용할 수 있습니다.
- Lua 스크립트 지원: 서버 측에서 복잡한 연산이나 트랜잭션 작업을 원자성(Atomicity)을 유지하며 안전하게 처리할 수 있습니다.
실무 주요 활용 사례
- 실시간 데이터 분석 및 랭킹 시스템: 데이터 구조를 활용해 실시간으로 변동되는 리더보드나 통계 데이터를 빠르게 처리합니다.
- 세션 관리 및 사용자 인증 정보 저장: 만료 시간(TTL) 설정이 용이하고 접근 속도가 빨라 세션 및 토큰 관리에 최적화되어 있습니다.
- Pub/Sub 기반 메시징 시스템: 실시간 채팅이나 서버 간 이벤트 알림 시스템 등에 폭넓게 사용됩니다.
장단점 분석
장점
- 유연성: 풍부한 데이터 구조를 지원하여 다양한 비즈니스 로직에 유연하게 대응할 수 있습니다.
- 안정성 보완: 데이터 영구 저장 옵션을 통해 인메모리 DB의 치명적 약점인 휘발성(데이터 유실)을 방지합니다.
- 압도적인 데이터 처리 속도: 대부분의 데이터 접근 및 조작 연산이 빠른 속도를 자랑합니다.
단점
- 관리의 복잡성 증가: 캐싱 외에도 다양한 기능(클러스터링, 영구 저장 설정 등)을 제공하므로, 설정과 인프라 관리가 다소 복잡해질 수 있습니다.
- 메모리 사용량 증가: 복잡한 데이터 구조를 모두 메모리에 적재하므로 메모리 소비가 크며, 이는 곧 인프라 비용 증가로 이어질 수 있습니다. 메모리 단편화 문제도 신경 써야 합니다.
아키텍처
싱글 (Standalone) 아키텍처
가장 단순한 형태의 기본 배포 모델로, 단 하나의 Redis 인스턴스(마스터)만 운영하는 구조입니다.
- 특징: 구조가 극도로 단순하며, 별도의 복제나 동기화 오버헤드가 없어 지연 시간이 가장 낮고 가볍습니다.
- 한계 (SPOF): 단일 장애점(SPOF, Single Point of Failure) 문제가 존재합니다. Redis 인스턴스가 다운되거나 서버에 문제가 생기면 전체 서비스의 캐시/데이터 계층이 마비됩니다.
- 용도: 개발 환경, 토이 프로젝트, 혹은 데이터가 유실되거나 일시적으로 서비스가 중단되어도 무방한 단순 임시 캐싱 용도에 적합합니다.

센티넬 (Sentinel) 아키텍처
싱글 구조의 최대 약점인 고가용성(HA, High Availability) 문제를 해결하기 위해 도입된 모델입니다. 마스터-복제(Master-Replica) 구조에 모니터링 전용 노드인 센티넬(Sentinel) 프로세스를 추가로 배치합니다.
- 특징 (자동 장애 조치): 센티넬 노드들이 마스터의 상태를 상시 감시합니다. 마스터 노드가 다운되면 센티넬들이 투표(Quorum)를 거쳐 정상적인 복제(Replica) 노드 중 하나를 새로운 마스터로 자동 승격(Failover)시킵니다.
- 읽기/쓰기 분리: 쓰기 작업은 마스터가 전담하고, 읽기 작업은 복제 노드들이 나누어 처리하여 읽기 트래픽을 분산할 수 있습니다.
- 한계: 고가용성은 보장되지만, 모든 마스터와 복제 노드가 전체 데이터를 동일하게 복제하여 들고 있기 때문에 용량의 한계가 존재합니다. 마스터 단일 노드의 메모리 용량 이상의 데이터를 저장할 수 없습니다.
클러스터 (Cluster) 아키텍처
고가용성뿐만 아니라, 데이터의 대용량화와 대규모 트래픽 확장을 모두 만족하기 위한 엔터프라이즈급 배포 모델입니다. 데이터를 여러 마스터 노드에 쪼개어 저장하는 샤딩(Sharding) 기술이 핵심입니다.
- 특징 (데이터 샤딩 및 데이터 슬롯): Redis 클러스터는 총 16,384개의 가상 해시 슬롯(Hash Slot)을 가집니다. 이를 여러 마스터 노드가 나누어 관리합니다. 데이터를 저장할 때 키(Key)의 해시값에 따라 해당 슬롯을 담당하는 마스터 노드로 자동 분산 저장됩니다.
- 자체 Failover 메커니즘: 각 마스터 노드는 자신만의 복제(Replica) 노드를 가집니다. 특정 마스터 노드가 다운되면 외부 센티넬 없이도 클러스터 내부의 다른 마스터 노드들이 투표하여 해당 샤드의 복제 노드를 마스터로 승격시킵니다.
- 한계: 아키텍처가 매우 복잡하며, 클라이언트 라이브러리가 클러스터 모드를 명확히 지원해야 합니다. 여러 키를 동시에 처리하는 멀티 키 연산(MGET, MSET 등) 사용 시 키들이 서로 다른 노드에 속해 있으면 제약이 따릅니다.
| 비교 항목 | 싱글 (Standalone) | 센티넬 (Sentinel) | 클러스터 (Cluster) |
| 핵심 목적 | 최소한의 자원으로 단순 캐싱 | 자동 장애 조치 및 고가용성(HA) 보장 | 분산 샤딩 및 수평 확장성(Scale-out) 확보 |
| 데이터 분산 (샤딩) | ❌ 불가능 (단일 노드 저장) | ❌ 불가능 (전체 노드 데이터 복제) | ⭕️ 가능 (16,384개 해시 슬롯 분산) |
| 고가용성 (HA) | ❌ 지원 안 함 (장애 시 중단) | ⭕️ 자체 지원 (센티넬 기반 자동 Failover) | ⭕️ 자체 지원 (마스터-레플리카 샤드 구조) |
| 권장 최소 노드 수 | 1대 | 5대 (Master 1 + Replica 1 + Sentinel 3) | 6대 (Master 3 + Replica 3) |
| 읽기/쓰기 확장 | 확장 불가 (스케일 업만 가능) | 읽기 확장 가능 (Replica 추가) | 읽기 및 쓰기 모두 확장 가능 (Node 추가) |
| 클라이언트 복잡도 | 매우 낮음 | 낮음 (센티넬 연동 필요) | 높음 (해시 슬롯 라우팅 인식 필요) |
| 장점 | 구성 및 관리가 매우 단순하고 빠름 | 데이터 유실 최소화, 안정적인 HA 인프라 | 대용량 데이터 저장 가능, 유연한 트래픽 확장 |
| 단점 | 장애 발생 시 단일 실패 지점(SPOF)이 됨 | 쓰기 성능 및 메모리 저장 용량 확장 한계 | 대형 인프라 관리 비용 및 복잡성 증가 |
Redis 싱글스레드 동작
센티널, 클러스터로 아키텍처가 구성되어도 명령어 처리엔진은 싱글스레드로 동작합니다.
Redis가 싱글 스레드를 사용하는 건 인메모리 데이터베이스의 특징입니다.
- CPU가 아닌 메모리 속도가 병목: Redis의 데이터 처리는 너무 빠르기 때문에 연산 속도(CPU)가 부족해서 느려지는 경우는 거의 없습니다. 주로 네트워크 대역폭이나 메모리 접근 속도가 한계점이 됩니다. 따라서 멀티 스레드로 CPU를 혹사시켜도 극적인 성능 향상은 없습니다.
- 컨텍스트 스위칭(Context Switching) 오버헤드 제거: 여러 스레드를 띄우면 CPU가 스레드를 번갈아 가며 실행하기 위해 상태를 저장하고 불러오는 막대한 비용(컨텍스트 스위칭)이 발생합니다. 싱글 스레드는 이 낭비를 완전히 제거합니다.
- 동기화(Lock) 오버헤드 완벽 제거 (원자성 보장): 멀티 스레드 환경에서는 여러 스레드가 동시에 같은 데이터(예: 조회수 카운트)에 접근할 때 꼬이지 않도록 'Lock(잠금)'을 걸어야 합니다. 이 Lock 메커니즘 자체가 엄청난 병목을 유발합니다. Redis는 한 번에 하나씩만 순서대로 처리하므로 태생적으로 완벽한 원자성(Atomicity)을 보장하며, 복잡한 동기화 설계가 필요 없습니다.
그렇다면, 싱글 스레드로 어떻게 수만개의 동시요청을 처리할까요?
하나의 스레드만 일하는데 어떻게 대규모 웹 서비스의 트래픽을 감당할까요?
그 비밀은 I/O 멀티플렉싱(I/O Multiplexing)과 이벤트 루프(Event Loop)에 있습니다.
요리 주방으로 예를 든다면 점원은 카운터(멀티플렉서 - linux epoll 등)에 서서,
준비된 작업 요청만 이벤트 큐(Event Queue)에 넣고,
눈 깜짝할 새(마이크로초 단위)에 요리(명령어 처리)를 끝내서 내보냅니다.
대기 시간 없이 쉼 없이 일하는 이 구조 덕분에 초당 10만 건 이상의 명령을 단일 스레드로 처리할 수 있습니다.
하지만 최신 Redis는 부분적으로 멀티 스레드입니다.
- 네트워크 I/O (읽기/쓰기 및 파싱): 데이터를 네트워크 소켓에서 읽어오고 결과를 클라이언트에게 반환하는 작업은 병목이 되기 쉬워 멀티 스레드로 분산 처리하도록 개선되었습니다.
- 명령어 실행 (데이터 조작): 하지만 메모리에 접근해서 데이터를 읽고 쓰는 핵심 비즈니스 로직(SET, GET 등)은 여전히 무조건 싱글 스레드로 처리하여 원자성을 유지합니다.
Redis란? (레디스가 싱글쓰레드로 동작하는 이유)
🔸Redis란?레디스는 Remote dictionary server의 약자로 오픈소스, 고성능 key-value 인메모리 NoSQL 데이터베이스이다.주로 캐싱, 세션 관리, 메시지 브로커, 실시간 데이터 분석 등의 목적으로 사용된다.
jhzlo.tistory.com
인메모리 캐시 솔루션 전격 비교 및 캐시 운영 전략
Simcached
Redis, Memcached, ElastiCache 와 같은 분산캐시가 아닌,
한 서버(프로세스)에서 Hashmap, dict, LRU 등의 자료구조를 활용해 임시로 흉내낸 캐시 (slang)
| 구분 | Memcached | Redis |
| 개념 및 특징 | 다중 서버 환경에 최적화된 단순하고 빠른 분산 캐시 | 다양한 데이터 구조와 부가 기능을 제공하는 고성능 스토어 |
| 데이터 구조 | 단순 키-값 (Key-Value) | 문자열, 리스트, 해시, 셋, 정렬셋 등 다양함 |
| 영구 저장 (Persistence) | 불가 (순수 휘발성) | AOF, RDB 방식으로 디스크 저장 지원 |
| 확장성 | 손쉬운 수평 확장 (Scale-out) 가능 | 자체 클러스터링을 통한 분산 및 확장 가능 |
| 주요 사용 사례 | DB 쿼리 결과나 세션 등 단순하고 빠른 분산 캐싱 작업 | 실시간 리더보드, 복잡한 데이터 분석, Pub/Sub 메시지 브로커 |
실전 트러블 슈팅
클라이언트 사이드 캐싱 (Client-Side Caching)
Q. 클라이언트 사이드 캐싱을 어떻게 구현하며, 데이터 갱신은 어떻게 처리하나요?
로컬 메모리에 LRU(Least Recently Used) 캐시를 구현하여 만료되거나 용량 초과 시 삭제합니다.
Redis의 데이터가 변경되면 Pub/Sub 채널을 통해 알림을 받아 로컬 캐시를 갱신/무효화합니다.
Redis 데이터가 업데이트 될때, 클라이언트 캐시 업데이트방법 : Pub/Sub 채널 -> 알림 -> 갱신
이를 통해 캐시 히트율이 극도로 높고 변동이 적은 데이터의 경우,
Redis까지 가는 네트워크 I/O조차 아끼기 위해 애플리케이션 메모리(로컬)에 직접 캐싱합니다.
Redis 6.0 Tracking 기능:
최근 Redis는 자체적으로 클라이언트 사이드 캐싱을 지원하는 Tracking 기능을 제공하여,
키가 변경될 때 서버가 클라이언트에게 직접 무효화(Invalidate) 메시지를 보내주는 스마트한 구조를 구축할 수 있습니다.
핫키 (Hot Key) 문제와 분산 환경의 검색
Redis는 싱글 스레드로 동작하기 때문에,
특정 키에대해 수백만개의 트래픽이 몰리면, 싱글 스레드인 해당 서버는 일하다가 장애를 발생합니다.
이를 Hot Key 문제라고 합니다.
Q. 특정 키에 트래픽이 몰리는 Hot Key 문제가 발생하면 어떻게 해결하나요?
단일 키를 여러 키로 분산(Sharding)하거나 랜덤 값을 붙여 클러스터 전체로 트래픽을 흩어지게 합니다.
또는, 읽기 전용 복제본(Read Replicas)을 두어 읽기 트래픽을 스케일링합니다.
키 쪼개기(Sharding)
ticket_count 하나만 두는 게 아니라,
의도적으로 ticket_count:1, ticket_count:2, ticket_count:3 처럼 여러 개의 키로 잘게 쪼갭니다.
이 키들은 클러스터 내의 서로 다른 마스터 서버 3대에 분산되어 저장되므로 트래픽이 3분의 1로 완벽히 분산됩니다
Q. 키를 쪼갰을 때, 해당 키들은 어떻게 검색하나요?
특정 키를 찾기 어려워 SCAN 명령어를 쓰면 전체 성능이 저하됩니다.
대신 메타데이터(Metadata)를 별도의 공간에 저장하여 관리합니다.
핫키는 단일 스레드인 Redis 노드 하나를 100% 점유하여 전체 클러스터를 마비시킬 수 있습니다
메타데이터를 저장하는 방식 외에도,
클라이언트 해싱(Client-side hashing)을 통해
백엔드 서버(클라이언트)가 Redis에 위치를 물어보는 대신,
자체적인 수학 공식(예: 유저 ID % 3)을 돌려 스스로 목적지를 계산합니다.
key:1, key:2 형태로 타겟 노드에 다이렉트로 요청을 해서 오버헤드없이 일관성 있게 라우팅하는 방식이 실무에서 자주 쓰입니다.
분산 잠금(Distributed Lock)과 동시성 제어
Q. Redis를 사용한 분산 잠금 알고리즘인 Redlock은 완벽하게 안전한가요?
Redis가 제공하는 RedLock을 알아보자
RedLock은 분산 환경에서 Redis가 권장하는 Lock을 제공하는 방법이다. 이 포스팅에서는 Redis Set 명령어에 NX 옵션을 통한 Lock을 제공하는 방법과 한계, RedLock의 특징 및 한계에 대해 정리하겠다.
medium.com
완벽하게 안전하지 않습니다.
TTL(Time To Live)이 벽시계(Wall-clock)에 의존하므로 서버 간 시간 동기화 문제가 발생할 수 있으며,
가비지 컬렉션(GC) 퍼즈 등으로 인해 잠금 해제 전에 다른 클라이언트가 락을 획득하는 이슈가 있습니다.
이슈상황
- Client A가 Redis로부터 10초짜리 잠금(Lock)을 획득합니다.
- 직후, Client A의 서버 애플리케이션에서 무거운 가비지 컬렉션(GC)이 발생하여 서버가 8초 동안 완전히 멈춥니다(Stop-the-world).
- 그 사이 Redis에 설정된 잠금의 유효시간(TTL) 10초가 만료되어 잠금이 풀립니다.
- Client B가 들어와서 비어있는 잠금을 새롭게 획득하고, 원본 DB의 데이터를 수정(결제 완료 등)합니다.
- 문제 발생: 8초 뒤 깨어난 Client A는 '자신이 아직 잠금을 쥐고 있다고 착각'합니다. 그리고 원본 DB의 데이터를 수정해 버립니다.
- 결과: Client B가 정상적으로 처리한 데이터가 덮어씌워지며 데이터 오염(Data Corruption)이 발생합니다.
대안으로 펜싱 토큰(Fencing Token)을 사용하거나,
-> 잠금을 줄 때 '절대 줄어들지 않는 대기표 번호(토큰)'를 같이 줍니다. DB는 항상 최신 대기표만 받도록 설정하여, 기절했다가 뒤늦게 온 A 서버의 옛날 번호표를 튕겨냅니다.
분산 환경에서 데이터 일관성이 절대적으로 중요한 시스템(돈이 오가는 결제, 항공권 중복 예약 방지 등)이라면
시스템의 근본적인 철학을 따져봐야 합니다
- Redis (AP 시스템): '정합성(C)'보다 '가용성(A)'과 '속도'를 우선합니다. 노드 간 데이터 동기화가 비동기로 일어나므로 찰나의 순간 데이터가 다를 수 있습니다. 초당 만 번의 '좋아요' 처리나 처리율 제한 장치(Rate Limiter)에 훨씬 적합합니다.
- Zookeeper / etcd (CP 시스템): '가용성(A)'이 조금 떨어져 느려지더라도 '완벽한 정합성(C)'을 보장합니다. 분산 합의 알고리즘(Raft 등)을 사용하여 과반수의 노드가 동의해야만 데이터를 저장합니다. 속도보다 절대 데이터가 꼬이면 안 되는 분산 락 환경에 적합합니다.
예약 시스템이나 결제처럼 절대 중복 처리가 되면 안 되는 경우 Redis(AP 시스템)보다 Zookeeper/etcd(CP 시스템)가 적합합니다.
- 아주 단순한 동시성 제어는 Redis의 INCR, SETNX(Set if Not eXists),
DEL 명령어를 활용한 스핀 락(Spin Lock)으로도 가볍게 구현할 수 있습니다.
[OS] Spin Lock (스핀락)에 대해 알아보자
개요 때는... 2023년 5월 24일. MeetCoder 10기 첫번째 밑업을 진행하던 중이었다. 민철님의 '분산락을 이용한 동시성 이슈 해결' 발표가 진행되던 중 채팅창에 요런 질문이 나왔다. 스핀락...? 스핀락이
hogwart-scholars.tistory.com
내구성 보완 (Persistence)
Q. Redis의 부족한 내구성을 보완하려면 어떻게 해야 하나요?
AOF (Append Only File)
모든 쓰기 연산을 로그로 기록합니다. (데이터 유실은 적지만 파일이 커지고 복구 속도가 느려 주의가 필요합니다.)
- RDB (Snapshot): 특정 시점의 메모리 상태를 디스크에 통째로 저장합니다.
- 복제 (Master-Slave): 마스터의 데이터를 슬레이브로 복제하여 가용성을 높입니다.
상황별 최적의 데이터 구조 활용
Q. Redis의 다양한 기능과 자료구조는 구체적으로 어떤 상황에 유용하나요?
- Pub/Sub: 실시간 알림, 이벤트 브로커, 실시간 채팅, 서버 간 캐시 동기화에 유리합니다. (단, 메시지가 유실될 수 있는 Fire-and-Forget 구조입니다.)
- Stream: Pub/Sub의 단점을 보완한 로그 데이터 구조로, 광고 클릭 데이터 같은 실시간 데이터 분석이나 메시지 큐(Message Queue) 처리에 적합합니다.
- Sorted Set (ZSET): 점수(Score)를 기반으로 자동 정렬되므로 실시간 랭킹(리더보드) 시스템에 필수적입니다.
Q. Sorted Set을 활용해 Rate Limiter(처리율 제한 장치)를 어떻게 구현하나요?
https://velog.io/@harukaseasons/Rate-Limiter-algorithms
Rate Limiter 알고리즘 정리
Rate Limiter는 특정 시간 동안 허용되는 요청의 수를 제한하는 메커니즘입니다. API 서버에서 과도한 요청으로부터 시스템을 보호하고, 공정한 자원 사용을 보장하기 위해 사용됩니다.동작 원리고
velog.io
처리율 제한장치 (Rate Limiter)
Rate Limiter는 특정 시간 동안 허용되는 요청의 수를 제한하는 메커니즘입니다.
API 서버가 과부하에 걸리지 않도록 방어하는 문지기(Rate Limiter)를
Sliding Window Log 알고리즘과 Redis의 Sorted Set을 이용해 구현할 수 있습니다.
Sliding Window Log 알고리즘
규칙은 최근 5분(윈도우 크기) 동안 3명(허용 한도)까지만 입장 가능입니다.
- (기록) ZADD: 손님이 오면 문지기는 방명록에 손님의 '도착 시간'을 점수(Score)로 적어둡니다.
- (청소) ZREMRANGEBYSCORE: 지기는 방명록을 보고 현재 시점 기준 5분이 지난 옛날 기록은 지우개로 싹 지웁니다.
- (계산) ZCARD: 현재 방명록에 남은 사람 수를 셉니다.
- (판단): 3명 이하라면 통과, 초과했다면 요청을 차단합니다.
실제 운영 환경에서는 수많은 유저가 동시에 접근하므로, 1~4단계의 과정이 실행되는 찰나의 순간에 데이터가 꼬일 수 있습니다.
이를 방지하기 위해 실무에서는 저 명령어들(ZADD, ZREMRANGEBYSCORE, ZCARD)을
Redis Lua Script로 묶어서 원자적(Atomic)으로 한 번에 실행하도록 구현하는 것이 표준입니다.
'devops' 카테고리의 다른 글
| 일관된 해싱, 해시 링, 해시 슬롯 (0) | 2026.06.02 |
|---|---|
| [시스템설계] 메시지 큐, 큐 시스템, 분산 큐 (0) | 2026.05.24 |